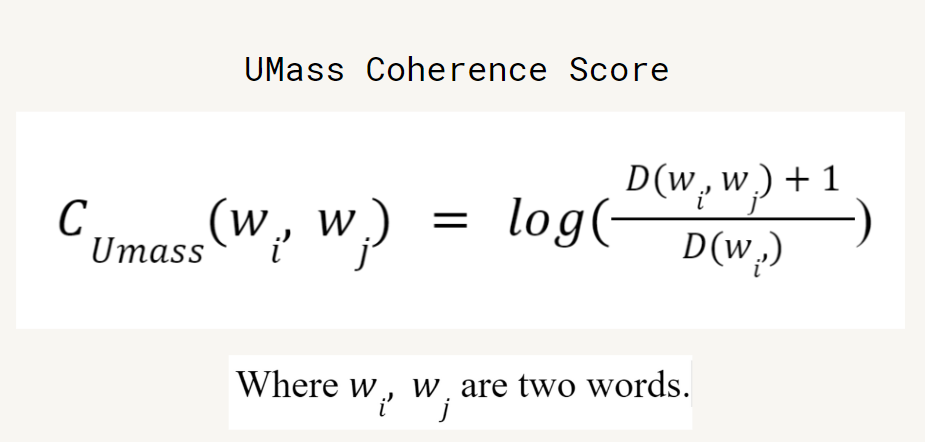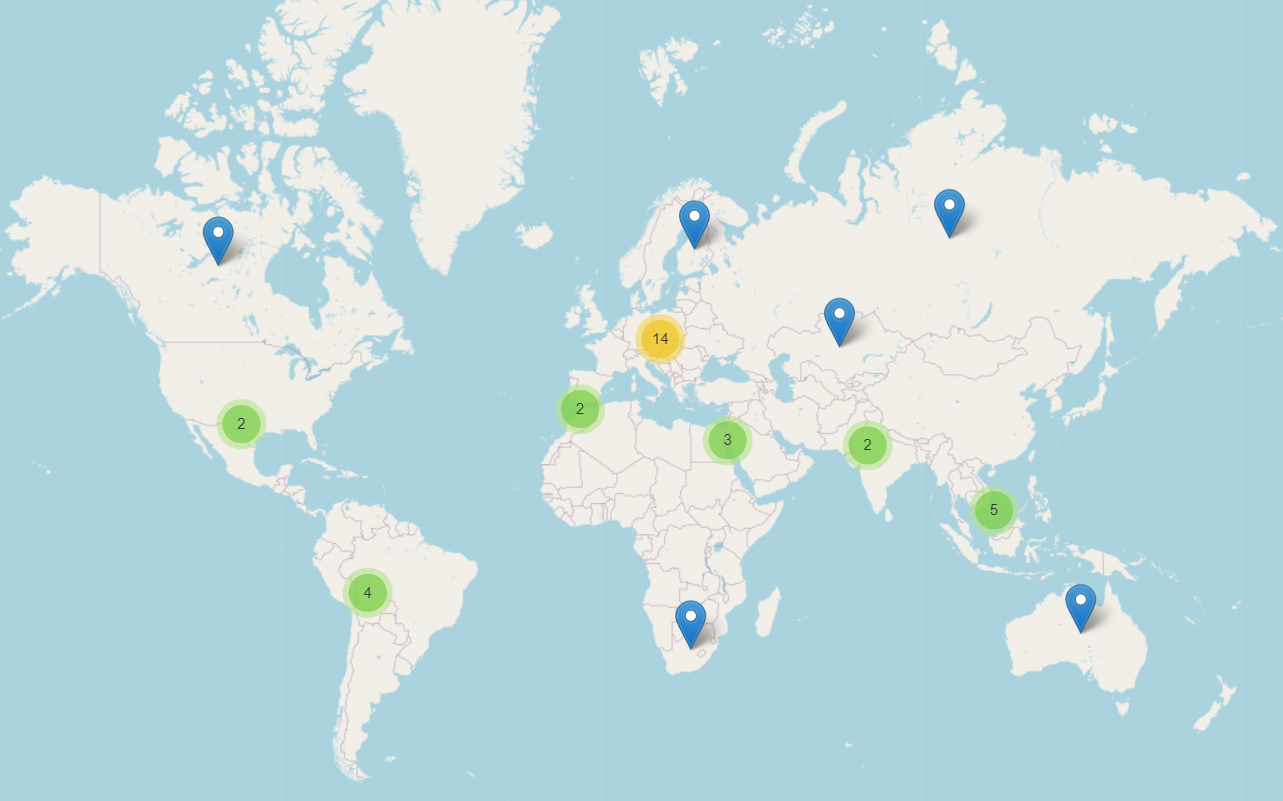
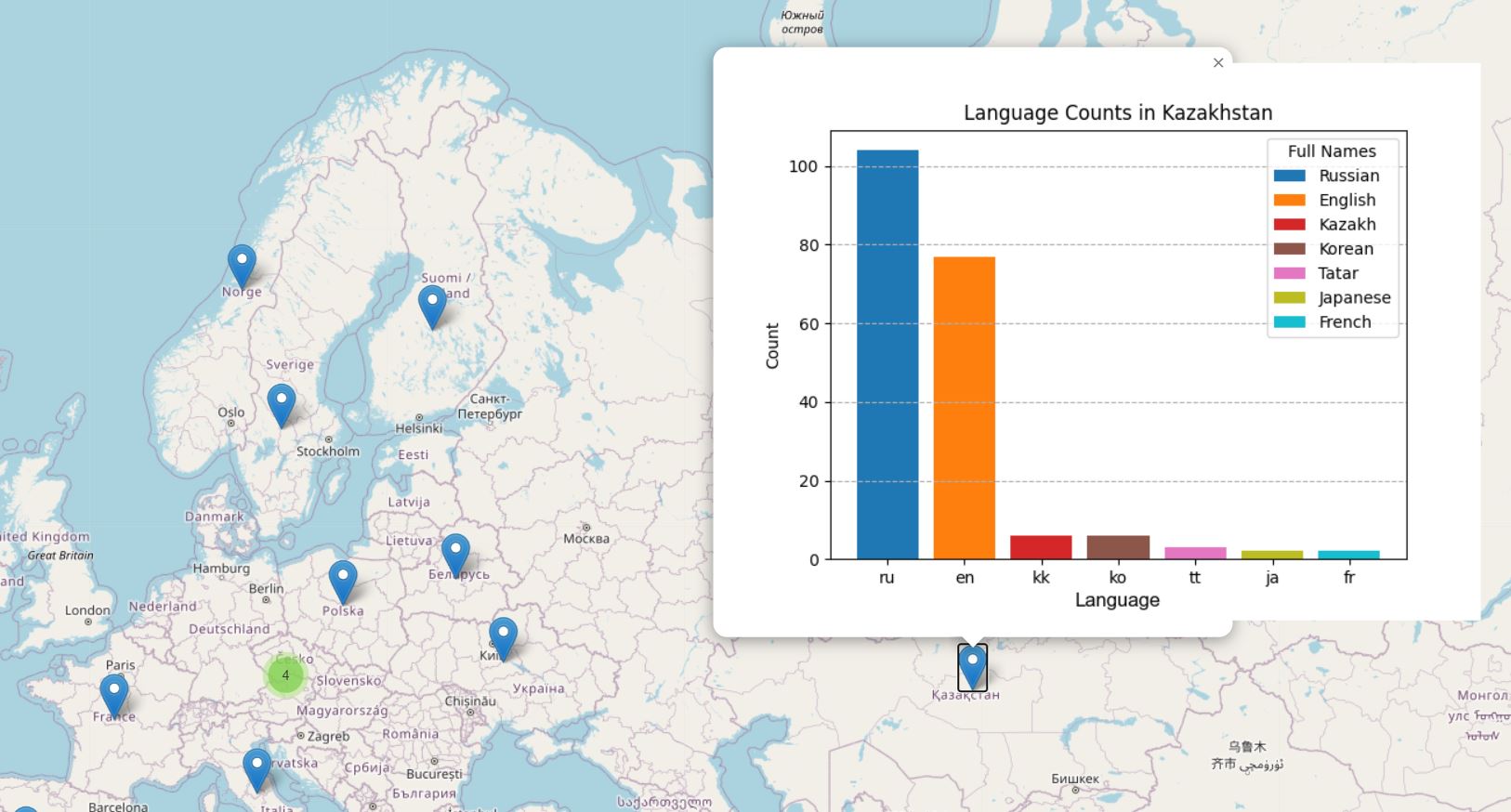





I took top-200 songs popular in each of the 38 countries. To select the songs, I used Spotify's weekly total charts and selected the most popular songs of all times* for that country.
Then I scraped the lyrics, translated them to English and preprocessed using basic techniques (tokenization, lemmatization, lowercasing, deleting punctuation and stop-words**). Then I applied topic modeling using LDA (Latent Dirichlet Allocation) to get the topics for each country.
Tools utilized:
- Genius API - to scrape the lyrics of the songs;
- Google Translate API - to translate the lyrics to English;
- Gensim library - for topic modeling;
- pyLDAvis library - to visualize the results;
- Kworb.net - for the names of the songs
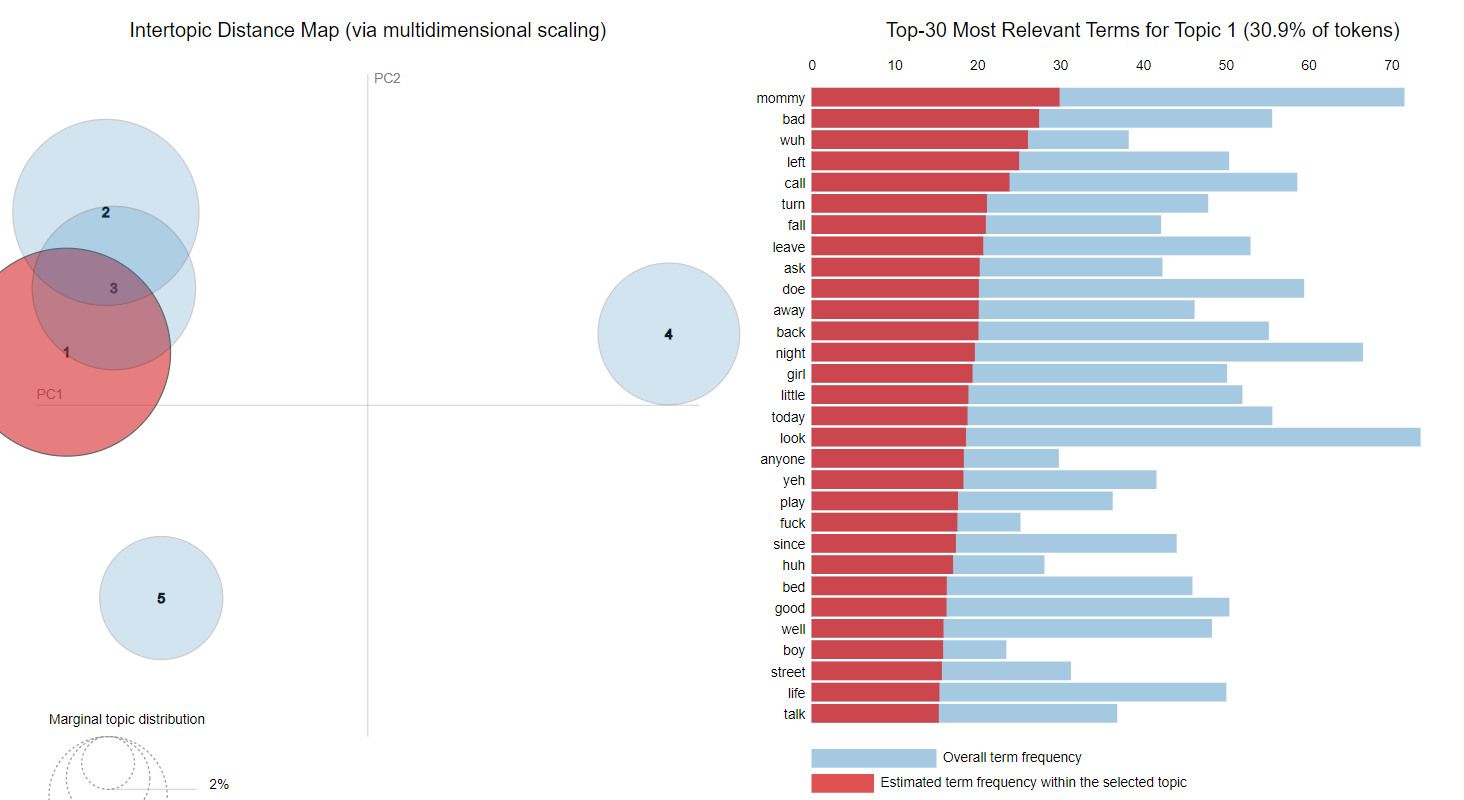
The very first results were pretty meaningless (image below), so I had to go through many iterations of preprocessing to start seeing some coherence it topics.
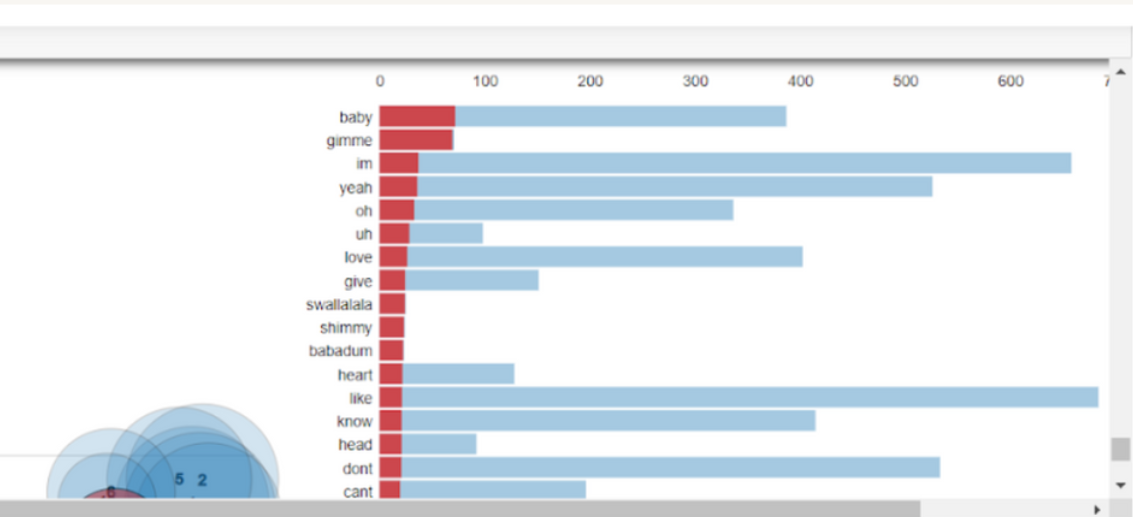
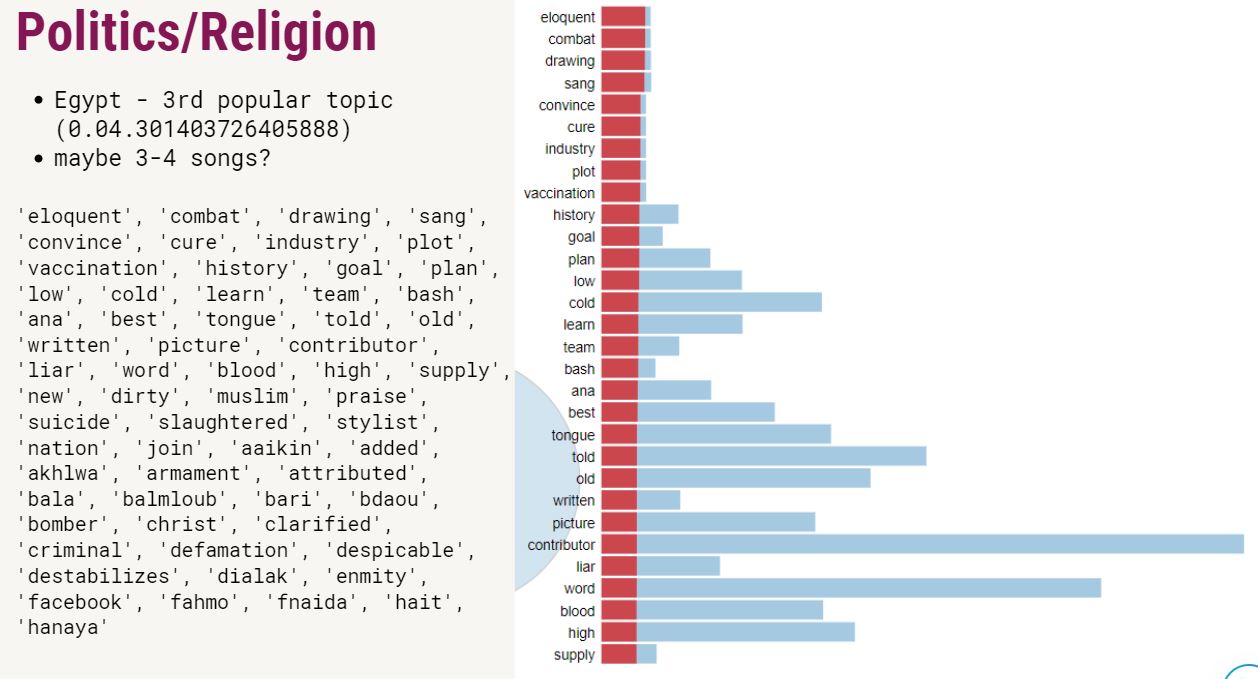
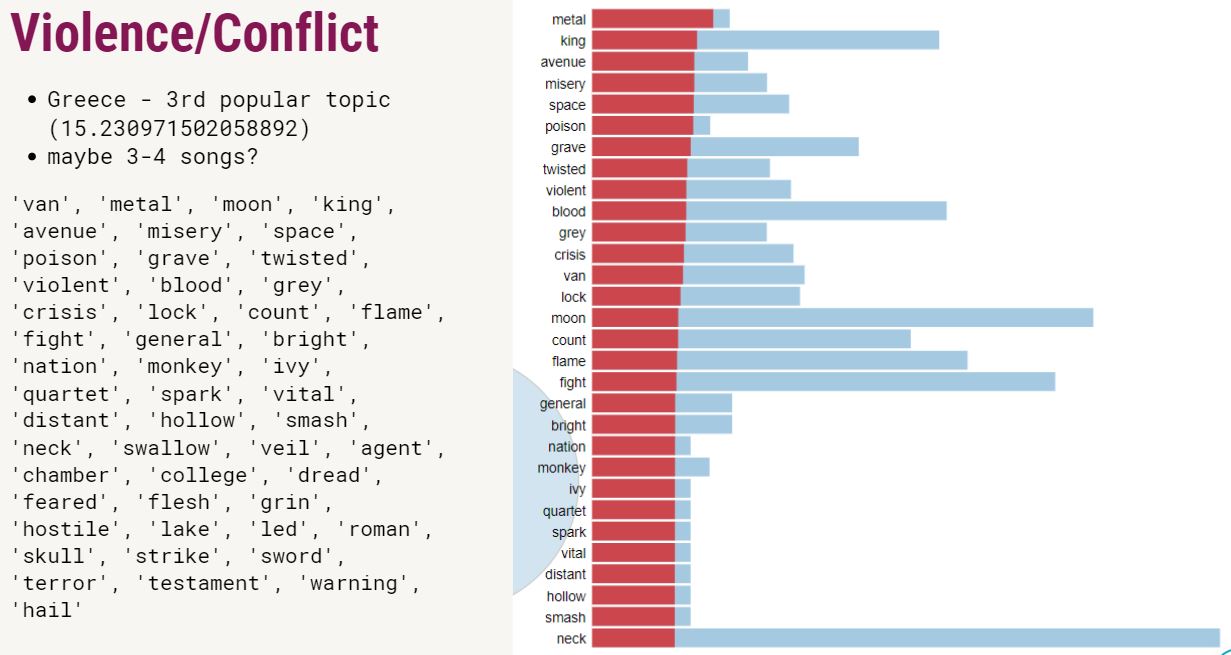
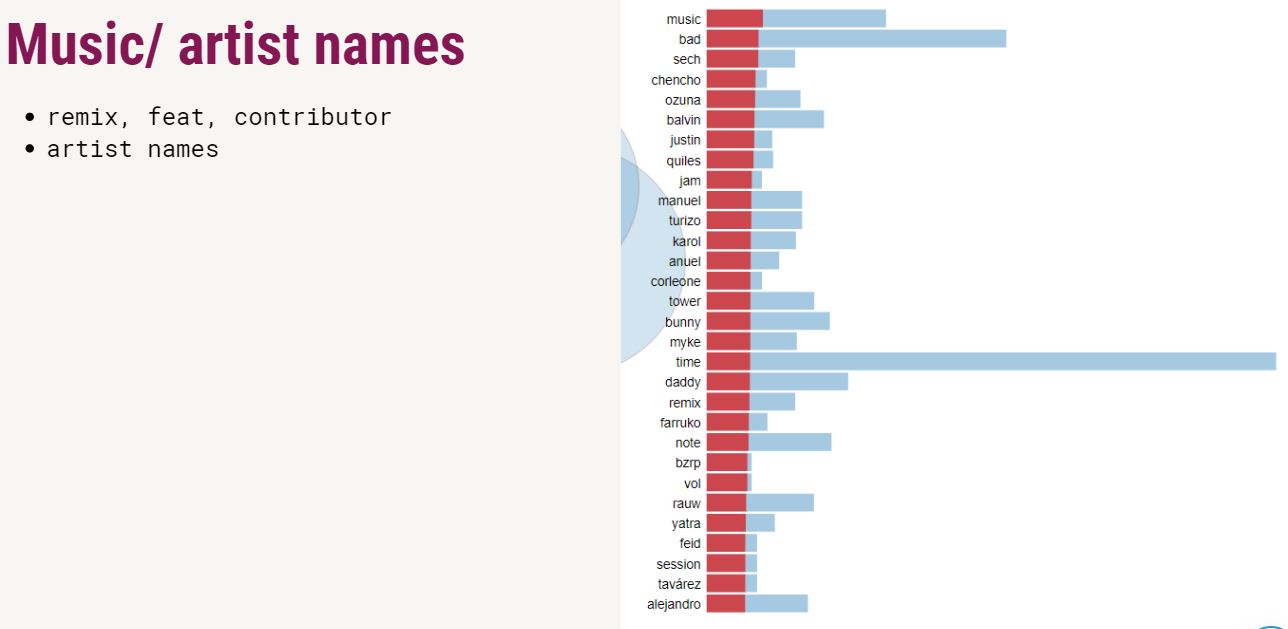
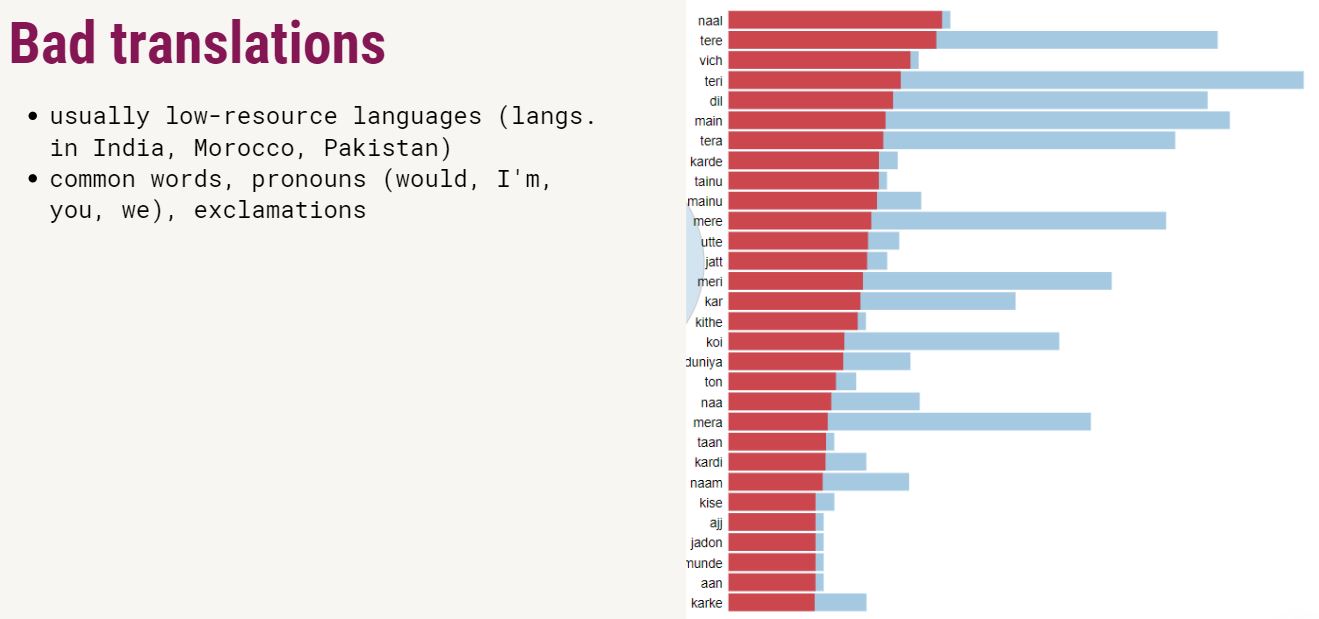
Just like in many other unsupervised methods, in LDA, we can't directly see the name or the topic of the cluster: instead, we have to label them ourselves. Naming the topics was one of the hardest parts! Click on the results to see what I found out.
*from the moment Spotify entered the country till March 2023
**I also used filter_extremes function from gensim module to eliminate the most common words (that are met in more than 50% of the documents) and the least common, rather eccentric/too specific words (that are met in less than 3 documents) – for example, names of the entities, rare words (like “pathointelligence” or “bermuda triangle”), etc. The function also takes only the top N words from the remaining corpus (in my case, N was set to 15 000).